

Vous avez un Mac et vous souhaitez personnaliser l’apparence de vos dossiers ? Nous allons vous montrer comment changer la couleur des dossiers sur Mac, en utilisant différentes méthodes simples et efficaces.
Que vous souhaitiez modifier l’icône, la couleur de fond ou l’étiquette du dossier, on vous explique en détaille comment vous pouvez le faire sur votre mac !
Comment changer l’icône du dossier sur Mac ?
L’une des méthodes les plus simples pour changer la couleur des dossiers sur Mac est de modifier l’icône du dossier. Il existe deux façons de le faire : la méthode classique avec le menu Lire les informations, et la méthode alternative avec l’application Aperçu. Voici comment procéder :
1. La méthode la plus facile
Cette méthode consiste à copier-coller une nouvelle icône sur l’ancienne, en utilisant le menu “Lire les informations“.
Pour cela, il faut suivre ces étapes :
- Sélectionnez le dossier dont vous voulez changer l’icône, puis faites un clic droit et choisissez “Lire les informations“.
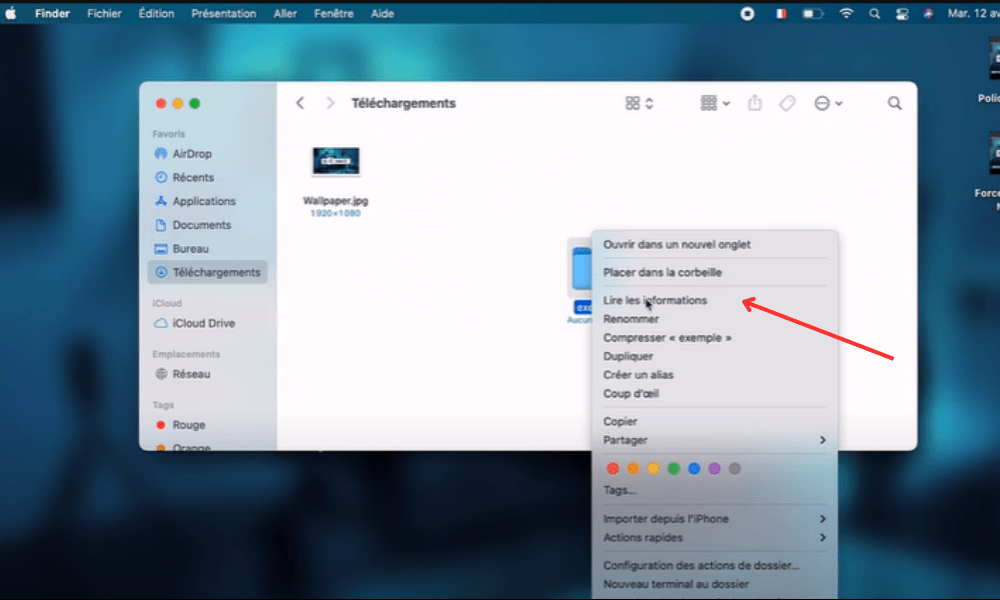
- Dans la fenêtre qui s’ouvre, cliquez sur l’icône du dossier en haut à gauche, puis appuyez sur les touches Commande + C pour la copier.
- Ouvrez l’image que vous voulez utiliser comme nouvelle icône dans une autre fenêtre du Finder ou dans une application comme Aperçu.
- Sélectionnez l’image, puis appuyez sur les touches Commande + C pour la copier.
- Revenez à la fenêtre Lir les informations du dossier, cliquez sur l’icône du dossier en haut à gauche, puis appuyez sur les touches Commande + V pour la coller.
- Fermez la fenêtre Lire les informations. Vous verrez que l’icône du dossier a changé.
2. Méthode alternative
Cette méthode consiste à utiliser l’application Aperçu pour modifier directement l’image du dossier et lui appliquer une nouvelle couleur.
Pour cela, il faut suivre ces étapes :
- Sélectionnez le dossier dont vous voulez changer l’icône, puis faites un clic droit et choisissez Afficher le contenu du paquet.
- Dans la fenêtre qui s’ouvre, accédez au dossier Contents > Resources et repérez le fichier nommé icon.icns. Il s’agit de l’image du dossier.
- Faites un clic droit sur le fichier icon.icns et choisissez Ouvrir avec > Aperçu.
- Dans l’application Aperçu, cliquez sur le menu Outils et choisissez Ajuster la couleur.
- Dans la fenêtre qui s’ouvre, utilisez les curseurs pour modifier la teinte, la saturation, la luminosité, le contraste ou la température de l’image. Vous verrez que la couleur du dossier change en temps réel.
- Une fois que vous avez obtenu la couleur souhaitée, fermez l’application Aperçu et enregistrez les modifications.
- Fermez la fenêtre du contenu du paquet. Vous verrez que l’icône du dossier a changé.
Si vous ne voulez pas créer vous-même vos icônes de dossiers, vous pouvez aussi en télécharger sur des sites web spécialisés, comme IconArchive, Flaticon ou Icons8. Vous y trouverez des milliers d’icônes gratuites ou payantes, de différents styles et de différentes couleurs, que vous pourrez utiliser pour personnaliser vos dossiers. Vous pouvez aussi utiliser des applications comme Iconizer ou Image2icon, qui vous permettent de créer facilement des icônes à partir de vos propres images.
Comment changer la couleur du dossier sur Mac à l’aide de l’aperçu ?
Toujours avec l’application Aperçu, encore plus rapide et plus facile que la précédente, cette méthode ne nécessite pas de copier-coller ni de modifier le contenu du paquet. Voici comment faire :
- Les étapes à suivre pour modifier la couleur d’un dossier existant :
- Sélectionnez le dossier dont vous voulez changer la couleur, puis faites un clic droit et choisissez Ouvrir avec > Aperçu.
- Dans l’application Aperçu, cliquez sur le menu Outils et choisissez Ajuster la couleur.
- Dans la fenêtre qui s’ouvre, utilisez les curseurs pour modifier la teinte, la saturation, la luminosité, le contraste ou la température de l’image. Vous verrez que la couleur du dossier change en temps réel.
- Une fois que vous avez obtenu la couleur souhaitée, fermez l’application Aperçu et enregistrez les modifications.
- Les astuces pour créer un nouveau dossier coloré :
- Sélectionnez un dossier quelconque, puis faites un clic droit et choisissez Dupliquer.
- Renommez le dossier dupliqué comme vous le souhaitez.
- Suivez les étapes décrites ci-dessus pour changer la couleur du dossier dupliqué avec l’application Aperçu.
Bon à savoir : Comment avoir Snapchat sur Mac – MacBook ?
FAQ
Comment changer la couleur de fond du dossier ?
Pour changer la couleur de fond, il faut modifier les options d’affichage du dossier. Cette méthode vous permet de choisir une couleur de fond pour chaque dossier, indépendamment de l’icône ou de l’étiquette.

Voici comment faire :
- La procédure pour accéder aux options d’affichage du dossier :
- Ouvrez le dossier dont vous voulez changer la couleur de fond, puis cliquez sur le menu Présentation et choisissez Options d’affichage.
- Dans la fenêtre qui s’ouvre, cochez la case Couleur de fond, puis cliquez sur le carré de couleur à droite.
- Le choix de la couleur de fond depuis la palette ou le sélecteur :
- Dans la fenêtre qui s’ouvre, vous pouvez choisir une couleur de fond depuis la palette proposée, ou cliquer sur le bouton Sélecteur de couleurs pour accéder à plus d’options.
- Dans le sélecteur de couleurs, vous pouvez utiliser les différents modes (roue, échelle, crayon, etc.) pour trouver la couleur qui vous convient, ou entrer directement le code hexadécimal de la couleur dans le champ correspondant.
- Une fois que vous avez choisi votre couleur de fond, fermez la fenêtre du sélecteur de couleurs et la fenêtre des options d’affichage. Vous verrez que la couleur de fond du dossier a changé.
L’impact de la couleur de fond sur la lisibilité des fichiers :
Lorsque vous changez la couleur de fond d’un dossier, il faut veiller à ce que les fichiers qu’il contient restent lisibles. Pour cela, il faut éviter les couleurs trop proches de celles des icônes ou des noms des fichiers, ou qui créent un effet d’éblouissement ou de camouflage.
Comment colorer vos dossiers sur Mac à l’aide d’étiquettes ?
Pour changer la couleur des dossiers sur Mac vous pouvez utiliser le système d’étiquettes intégré à Mac OS. Cette méthode vous permet d’attribuer une étiquette colorée à chaque dossier, ce qui peut vous aider à les classer par catégorie, par priorité ou par statut.

Voici comment faire :
- Faites un clic droit sur le dossier et choisissez Étiquette dans le menu contextuel. Sélectionnez ensuite la couleur que vous voulez lui attribuer.
- Sélectionnez le dossier et cliquez sur le menu Fichier. Choisissez ensuite Étiquette et sélectionnez la couleur que vous voulez lui attribuer.
- Sélectionnez le dossier et appuyez sur les touches Commande + I pour ouvrir le menu Lire les informations. Cliquez sur l’icône Étiquette en haut à droite et sélectionnez la couleur que vous voulez lui attribuer.
- Sélectionnez le dossier et faites-le glisser vers l’icône Étiquette dans la barre latérale du Finder. Relâchez-le sur la couleur que vous voulez lui attribuer.
Comment personnaliser les noms et les couleurs des étiquettes ?
Si vous voulez personnaliser les noms et les couleurs des étiquettes, vous pouvez suivre ces étapes :
- Cliquez sur le menu Finder et choisissez Préférences.
- Dans la fenêtre qui s’ouvre, cliquez sur l’onglet Étiquettes.
- Vous verrez les sept étiquettes prédéfinies, avec leur nom et leur couleur.
- Cliquez dessus et tapez le nouveau nom.
- Cliquez sur le carré de couleur à droite et choisissez une nouvelle couleur dans la palette ou le sélecteur.
- Fermez la fenêtre des préférences.
Vous verrez que les étiquettes de vos dossiers ont changé.
Quelles sont les autres solutions pour changer la couleur des dossiers sur Mac ?
Si aucune des méthodes présentées ne vous convient, vous pouvez aussi opter pour des solutions alternatives, comme des applications dédiées à la personnalisation des dossiers. Il en existe plusieurs sur le marché, qui vous offrent plus de possibilités et de facilités pour changer la couleur des dossiers sur Mac.
Voici quelques exemples :
- Folder Color est une application qui vous permet de changer la couleur des dossiers en un clic. Vous pouvez choisir parmi 24 couleurs prédéfinies, ou créer vos propres couleurs personnalisées. Vous pouvez aussi appliquer des effets comme le dégradé, le flou ou le relief à vos dossiers.
- Folder Designer est une application qui vous permet de créer des icônes de dossiers originales et stylées. Vous pouvez utiliser des images, des textes, des emojis ou des symboles pour décorer vos dossiers. Vous pouvez aussi ajuster la taille, la forme, la rotation ou l’opacité de vos icônes.


